Visual regression testing using DOM analysis for increased performance.
Problem
When developing on a web application unintended side effects in the form of visual changesare likely to occur. The manual process for find-ing these issues is long and tedious and existingtools suffer from either bad recall or bad precision.
The most prevalent technique to define where there is a visual change is referred to as the pixel-by-pixel method and simply consists of comparing the individual pixels of two images. One image is taken before the change and the other image is taken after the code changes are applied. The idea behind this is that if a pixel has changed color, this must bean indicator that either an element has moved, been removed, changed property or state in some way
This novel approach suffers from 2 issues.
- We don’t know what the issue is and have no means of easily identify it.
- We are highly suceptible for the cascading error problem.
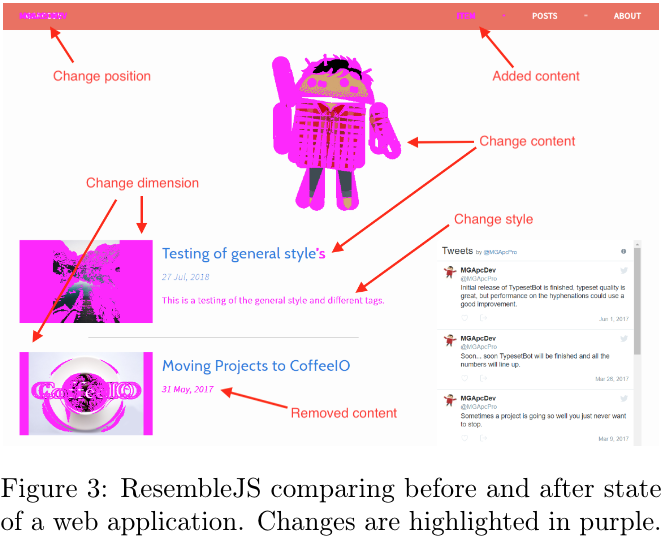
Here is the same test, but with 1 additional change. Header has added 20px padding on the bottom. Now test has too many false positives that to be useful for anything.

Solution
As part of my Master thesis a proof-of-concept was developed to demonstrate if the assumption: “Any visual change the enduser can perceive will appear as a change in the HTML or rendered CSS.” was correct.
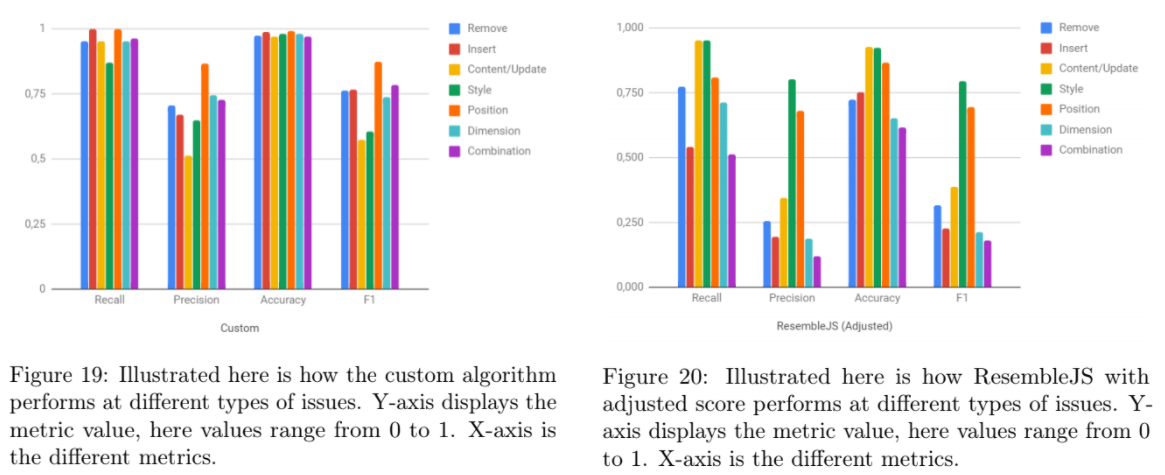
While the solution wasn’t perfect, it demonstrated a major improvement in most types of visual issues across all respected metrics.
Progress
The project is a multistep program.
- For capturing pages based on a list of viewport sizes and urls JavaScript is used.
- To compare stored captures, Python is used for performing tree analysis, subtree matching and DOM caparison.
- To visualize the initial solution was drawing an overlay on the website screenshots. Currently I’m working on a solution to dynamically take processed data from Python and created cross test summaries and dynamic overlaying.
(code and thesis paper is not publically awailable, email for more info mgapcdev@gmail.com)